For 2 questions on the Psychology Stack Exchange, I compared a standard “manual” literature review process using Google Scholar to 4 AI tools for generating references.
Note: I did not use AI to generate the answers. Rather, the AI tools were used to generate a list of references for the literature reviews.
AI tools given the question text as the prompt performed approximately the same as Google Scholar with the same prompt, and underperformed Google Scholar with subject-matter appropriate search criteria. One AI tool (Perplexity) did outperform Google Scholar on result ranking, but provided few actual results. Ultimately, AI is not yet ready to replace a manual literature review process.
Methods:
Manual: This method requires translating the original question to subject-matter appropriate search criteria, whereas AI tools use the question directly as the prompt. The results then need to be filtered. Additionally, searching is often an iterative process – with knowledge gained from initial search used to refine further queries. A comprehensive review also involves following citations (in both directions). These are all steps that AI could potentially automate.
Google Scholar: I used the original question text with stop words removed as the search words. This was included for comparison purposes only.
GS Keywords 1 & 2: These are Google Scholar searches done with subject-matter appropriate search criteria. This was also included for comparison purposes. Results ought to be more relevant than just pasting the original question text, and with minimal overlap between the 2 searches.
ChatGPT: I used the prompt: “Find 25 references that answer the question: “[Original question text]” Be accurate and true to the source.” ChatGPT often “hallucinates” references, and the request for accuracy decreases this problem. Results are limited to 2021.
GPT-4: I used the prompt: “Find 25 references that answer the question: “[Original question text]”.” GPT-4 is expected to outperform ChatGPT, with fewer “hallucinated” references (even without a request for accuracy), and more relevant results. Results are still limited to 2021.
Consensus: This tool is used exclusively to generate references, so the prompt can simply be the question itself. However, I found that adding the term “Review: [Original question text]” improves result ranking in favour of literature reviews. Unlike the GPT tools, this one is online, so all generated references are real.
Perplexity: I used the prompt: “Find 25 references that answer the question: “[Original question text]””; however, results were limited to 5 articles at a time, requiring multiple follow-up queries: “Find more unique references.” This tool is also online, so results are usually not hallucinated. While the relevance of results was not bad, repeated queries eventually led only to duplicates, so I stopped.
Coding:
- References not found on Google Scholar were marked Hallucinated.
- References not answering the question were marked Not Answered.
- Repeated references were marked Duplicate.
- References answering the question were marked as Answered. This is potentially subjective, as some papers claim to answer the question in theory, but I only included papers that answer the question empirically.
- References included in the literature review were marked Included. Basically I marked secondary or tertiary sources that answer the question as Included, and primary sources as Answered.
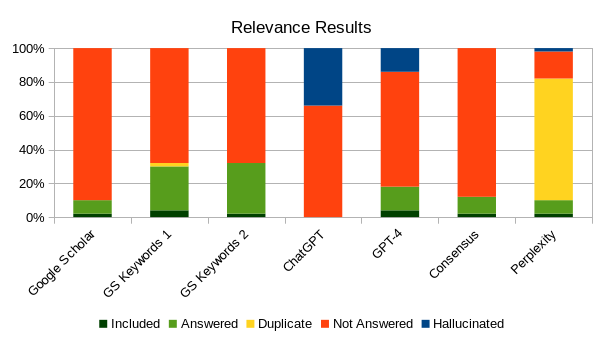
Note: The height of the green columns approximates the relevance of results achieved by each method.
Analysis:
I also ran correlations between each tool’s rank and relevance. ChatGPT produced results in alphabetical order, so was not included in this analysis.
| Method | Correlation |
|---|---|
| Google Scholar | -0.11 |
| GS Keywords 1 | -0.15 |
| GS Keywords 2 | -0.32 |
| GPT-4 | -0.33 |
| Consensus | -0.34 |
| Perplexity | -0.41 |
Conclusions:
The 3 Google Scholar searches are just for comparison – the full “manual” process involves more than this. Apart from ChatGPT, all the AI tools produced comparable results to uncustomized Google Scholar searches, but did not improve on them.
The manual process of following citations yielded 16 review papers for the posted answers. Initial Google Scholar searches included only 3 of these in the results, while combining the AI tools together, 4 additional review papers came up in the results. Thus, AI tools can potentially augment Google Scholar searches for more comprehensive coverage, but are not sufficient to replace the full manual process.
Finally, the rank correlation for Perplexity was significantly higher than Google Scholar search, suggesting that highly ranked results are more likely to be relevant. However, Perplexity provided few actual results.
Note that while I compared the original question text as prompt to both Google Scholar and the AI tools, I did not compare subject-matter appropriate search criteria to customized prompts. It is likely that prompts customized to each question (ie, analogous to the way search criteria is customized) could produce more relevant results, but I leave this for a future experiment. That said, not all AI tools accept such prompts, ChatGPT and GPT-4 are still limited to 2021, and having to customize prompts does not really reduce the work involved in the manual process anyway.